Index
- Image-Based Rendering Assisted Volume Rendering
- Architecture of Parallelization and IPC Framework
- OmniAxis View Capability
Image Based Rendering Assisted Volume Rendering
As part of the NGI-Combustion Corridor project, the LBL Visgroup has created an appliction that enables remote, distributed visualization of large, time-varying data volumes. Our approach is one that leverages a scalable, parallel volume rendering infrastructure that combines high-performance parallel machines remotely located from the user with graphics capabilities on the user's workstation. One of the primary goals of this project is to enable viewing of large, time-varying data volumes that are remotely located in such a way as to load-balance the end-to-end performance.
Our volume rendering engine uses an idea called "Image Based Rendering Assisted Volume Rendering," first presented by Roger Crawfis et. al. of Ohio State University. The fundamental idea behind IBRAVR is that large data is partially prerendered on a large computational engine close to the data, then final rendering is performed on a workstation. The shared-rendering model allows for some degree of interactivity on the local workstation without the need to recompute an entirely new image from all the data when the object is rotated by a small amount. What makes such local interaction possible is the "magic" of Image Based Rendering concepts. Our IBRAVR implementation consists of three fundamental components:
- Back-End, Data Access/Compositing-Rendering Engine
- Data readers are responsible for loading data from secondary, tertiary or network-based storage such as a DPSS (see DPSS reference) Ideally, implementation of the data reader will be in some form of multiprocessing, such as MPI, so as to achieve high I/O rates through parallelism. In addition to loading data, this component also perform image compositing of raw volume data. As the project proceeds, we will include a Drebin-Hanrahan style classifier/shader. Each of the data reading processes works with only a small subset of the overall data volume, so both data I/O and rendering performance scale well.
- Rendering Engine
- The rendering engine receives 2D images from the back-end data compositing engine. These images are assembled into a 3D representation that may be interactively transformed by a viewer. Our sample implementation runs on a wide range of workstations, including SGI, Sun-Solaris and garden variety x86 Linux boxes, both with and without graphics accelerators. Even on low-end hardware, we achieve reasonably interactive rendering rates. These rendering rates are possible only because of the distributed rendering architecture of our IBRAVR implementation.
- Network Interface
- The data and rendering engines are located on separate machines. They communicate using custom TCP/IP socket code. Most of the data transfers are large-payload (blocks of image data), with some small amount of control information used to negotiate configuration between the render and data engines. In our implementation, each processing element of the data engine communicates through a socket with a receiver thread in the rendering engine. Such a strategy results in a fully-saturated network.
- Data readers are responsible for loading data from secondary, tertiary or network-based storage such as a DPSS (see DPSS reference) Ideally, implementation of the data reader will be in some form of multiprocessing, such as MPI, so as to achieve high I/O rates through parallelism. In addition to loading data, this component also perform image compositing of raw volume data. As the project proceeds, we will include a Drebin-Hanrahan style classifier/shader. Each of the data reading processes works with only a small subset of the overall data volume, so both data I/O and rendering performance scale well.
This PowerPoint presentation has a few slides that shows all the system components.
Parallalization and IPC Details
Our viewer is parallelized using POSIX pthreads (do a "man pthread" on your favorite UNIX box for more info), while the back-end is parallelized using the MPI programming model. Our implementation uses the MPI (the Message Passing Interface) standard for parallel programming). Our Solaris and IRIX implementations use MPICH (see the MPI URL).
Parallelization on the back-end is used to accelerate software rendering. By and large, the rendering itself scales linearly with the number of processors. Factors that contribute to deviation from pure linear speedup include access to the data, and transmission of results to the viewer. Like all object-order parallel volume rendering algorithms, rendering speed increases nearly linearly with the number of available processors. Similarly, the results of each independent rendering is an image, and these images must be recombined into a final image for presentation to the user. Many different approaches have been used to solve the image combination problem (references need to be filled in, but include binary-swap, etc.)
The IBRAVR approach allows us, in principle, to avoid the explicit recombination of images inside the (back end) volume rendering framework. Instead, all the images (containing the final volume rendering of subsets of the total volume) are transmitted to a viewer. The viewer "recombines" the images using local graphics hardware vis-a-vis 2D texture mapping and alpha blending. The rendering thread of the viewer operates asynchronously from the rate at which the back end data engine can generate a stream of images of rendered subsets of the data volume, thus remains higly interactive irrespective of back-end rendering speed or network bandwidth.
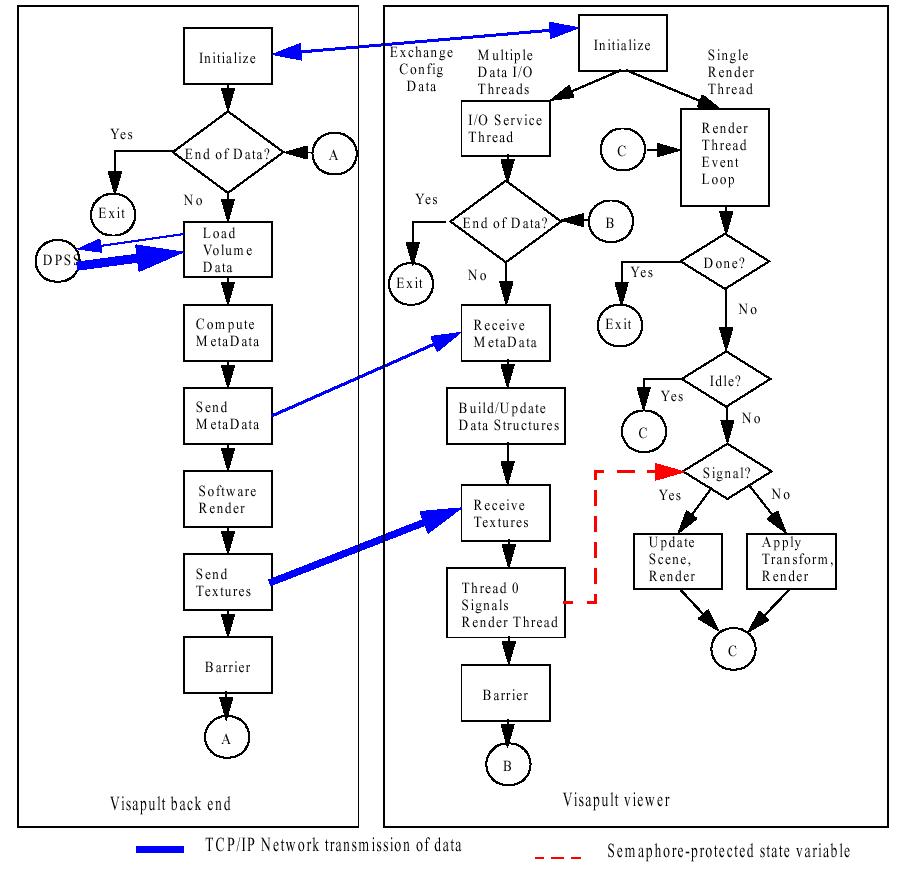
This following image shows a complete, functional block-level representation of the architecture of the Visapult viewer, the Visapult back end and IPC communication points. This picture is an accurate representation of the overall system as of 30 August 2000. For more detailed information, please refer to our SC00 paper
|
BackEnd Overlapped IPC Details
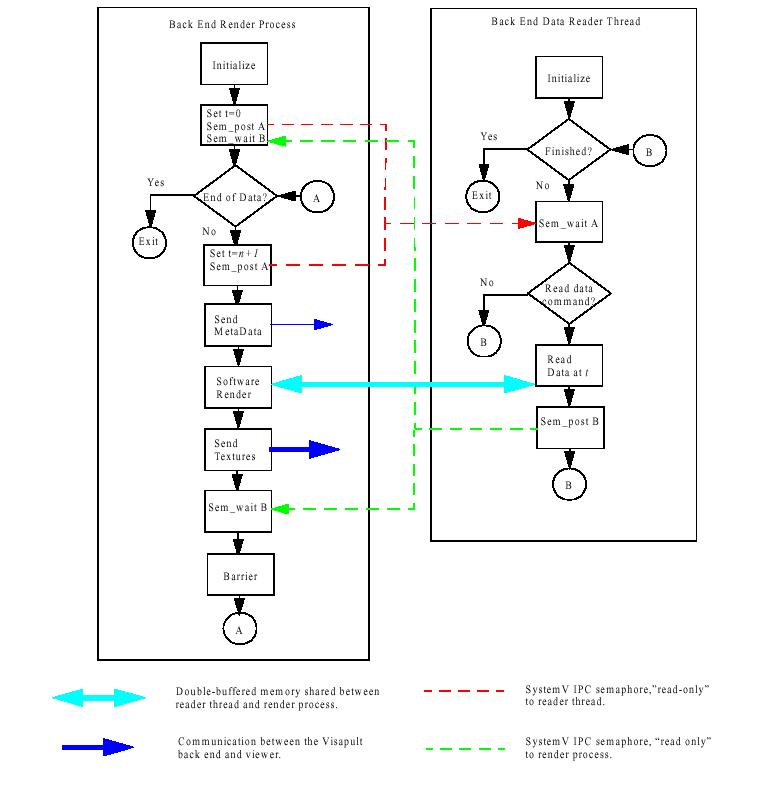
We have chosen to implement overlapped I/O and rendering in the Visapult back end using a combination of MPI and pthreads. In our case, the back end is an MPI job, and each MPI PE will create and control a freely-running, detached thread using POSIX threads, or pthreads.
For the discussion that follows, the term process refers to each process created by MPI. The number such processes is specified on the command line by the user at the time the MPI job is launched, and remains fixed for the duration of the run. In contrast, the term thread refers to the freely-running, detached pthread that is associated with each MPI process.
Upon creation, each thread enters into a processing loop. The thread is synchronized with it's controlling process using a pair SystemV semaphores, one that is set by the process and read by the thread, and another that is set by the thread and read by the process. The process will instruct the thread to either read data at time step T, or to quit. This command is placed into memory allocated off the heap by the process, so it is visible to both the thread and the process, and avoids the use of SystemV shm (for simplicity). For more details, please refer to our SC00 paper.
|
OmniAxis View Capability
August 30, 2000A fundamental limitation of our implementation to-date is that volume decomposition in the back end occurs only along the K-, or Z-axis of the volume data. The Visapult viewer's default view and orientation has the user looking down the Z axis of the data; when the user rotates the model, he sees the individual planes of geometry created by the IBRAVR process. A common and recurring request from users is the ability to look at the data from any view.
On June 23, we reported on the milestones page that an early prototype was working, but only for AVS data. Since that time, we have scrapped that design in favor of one that is more efficient. The June 23 design called for altering the way data was read in, then once the data was read in, the rest of the existing back end code could be used without any modification.
This approach was fine for AVS volumes - they can reach a maximum of 255x255x255 in size, and live in a disk file. However, for larger data files, particularly those on the DPSS, we realized that altering the way data was read in would be extremely inefficient. Note that data is physically stored in x-varies-fastest, then y, then z byte ordering. Therefore, when reading slabs of Z, a single lseek() followed by a single read() is sufficient to read in an entire subset of the volume data. Changing the way in which data is read in requires more lseek() and read() calls, and the size of the I/O buffer diminishes. Some systems such as the DPSS rely on large data block sizes to produce I/O efficiency.
OmniAxis Design SummaryEach back end PE will read in a subset of volume data, as if performing a z-axis decomposition. Reading data in this way is the most efficient, as it minimizes the number of seeks and reads, and relies on large I/O buffers. Once the data lands in each back end PE, some subset of the z-axis decomposition is rendered according to the current "best view axis" (this information is supplied to the back end by the Visapult viewer). Then, all back end PE's must reassemble partial images from other PEs into a single texture image, which is then broadcast to the peer process in the viewer. This approach will minimize the amount of MPI broadcast traffic. The only additional cost to the earlier Visapult implementation will be 1) the data reorganization stage, and that occurs only within each PE - no inter-PE communication is required, and 2) inter-PE communication of image fragments, rather than volume fragments.
On the viewer side, a scene graph is built initially that contains geometry used for each of the six primary view axes (+Z, -Z, +X, -X, +Y, and -Y). At render time, one of these six subtrees will be drawn, depending upon which axis of the model is most parallel to the viewing direction. The underlying scene graph technology supports this type of operation directly through node switch callbacks. As new textures arrive from the back end, they are stored into a texture table. There is a relationship between entries in the texture table and scene graph nodes, so that no explicit mapping is needed. The size of the texture table is known when the viewer starts, and does not change over the course of the job.
Ramifications of this DesignThe fundamental design goal we had in mind was to perform OmniAxis views for structured, regular volumes of data. An earlier implementation of Visapult had "hooks" in the code to support arbitrary size and placement of textures in 3-space - something we thought might be interesting for direct rendering of data from adaptive meshes. We have sacrificed that ability in favor of efficiency for the more common case of uniform volume data.